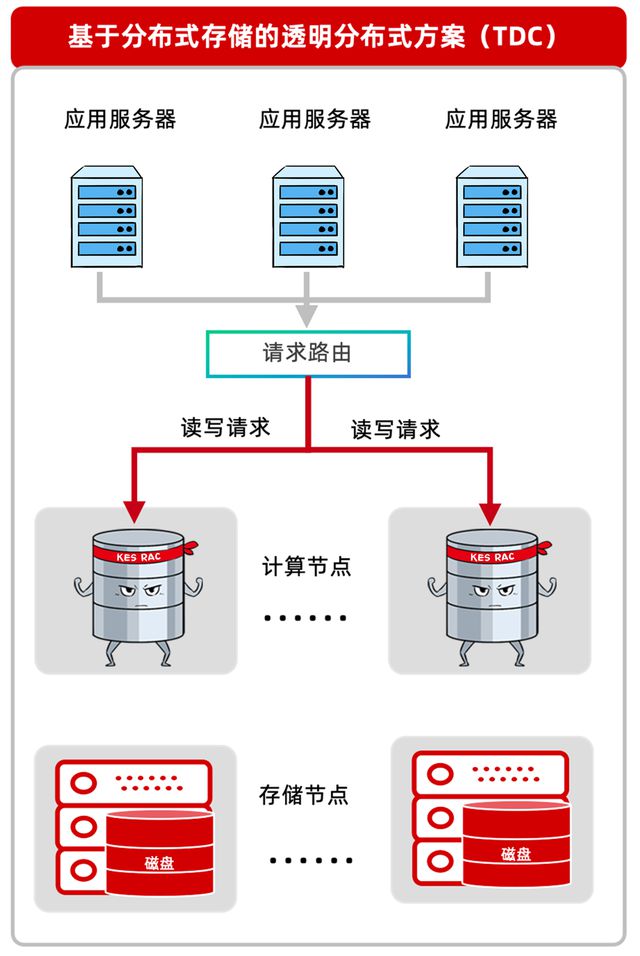
基于Hadoop與關(guān)系型數(shù)據(jù)庫的電力用采大數(shù)據(jù)混合服務(wù)架構(gòu)
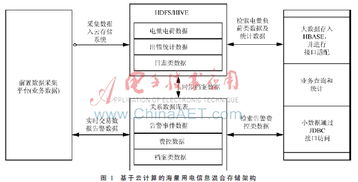
隨著智能電網(wǎng)的快速發(fā)展,電力用采系統(tǒng)每天產(chǎn)生海量的實(shí)時(shí)數(shù)據(jù),傳統(tǒng)的關(guān)系型數(shù)據(jù)庫在存儲(chǔ)和處理這些大數(shù)據(jù)時(shí)面臨性能瓶頸。為了應(yīng)對(duì)這一挑戰(zhàn),結(jié)合Hadoop分布式計(jì)算框架與關(guān)系型數(shù)據(jù)庫的混合服務(wù)架構(gòu)應(yīng)運(yùn)而生,成為電力用采大數(shù)據(jù)處理的高效解決方案。
一、混合架構(gòu)的設(shè)計(jì)理念
電力用采大數(shù)據(jù)混合服務(wù)架構(gòu)的核心在于充分發(fā)揮Hadoop和關(guān)系型數(shù)據(jù)庫各自的優(yōu)勢(shì)。Hadoop生態(tài)系統(tǒng)(如HDFS、MapReduce、Spark)擅長處理非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù),支持高吞吐量的批處理操作;而關(guān)系型數(shù)據(jù)庫(如MySQL、PostgreSQL)則適用于事務(wù)性操作、復(fù)雜查詢和數(shù)據(jù)一致性要求高的場(chǎng)景。通過將兩者結(jié)合,可以實(shí)現(xiàn)數(shù)據(jù)的分層存儲(chǔ)與處理:原始數(shù)據(jù)和歷史數(shù)據(jù)存儲(chǔ)在Hadoop中,而頻繁訪問的匯總數(shù)據(jù)、元數(shù)據(jù)和業(yè)務(wù)規(guī)則則保留在關(guān)系型數(shù)據(jù)庫中。
二、架構(gòu)組成與數(shù)據(jù)流向
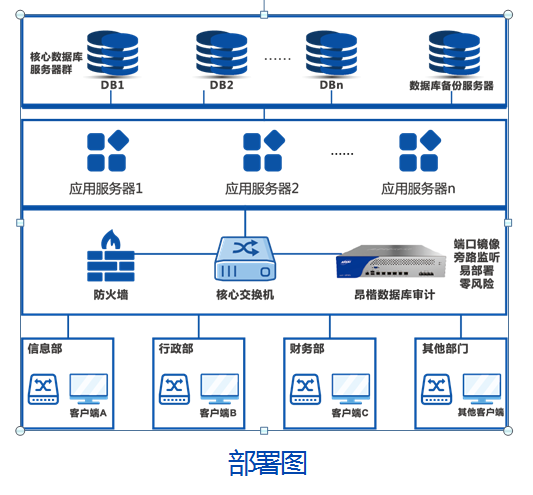
該混合架構(gòu)通常包括以下組件:
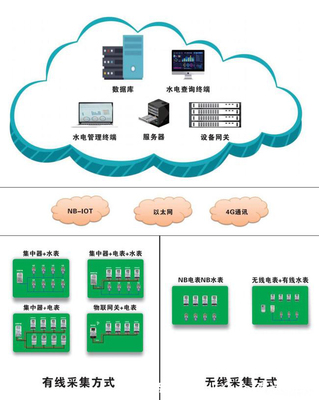
- 數(shù)據(jù)采集層:通過物聯(lián)網(wǎng)設(shè)備、智能電表等收集電力用采數(shù)據(jù),并傳輸至數(shù)據(jù)接入網(wǎng)關(guān)。
- 數(shù)據(jù)存儲(chǔ)層:原始數(shù)據(jù)首先進(jìn)入Hadoop分布式文件系統(tǒng)(HDFS),用于長期存儲(chǔ)和批量分析;同時(shí),關(guān)鍵業(yè)務(wù)數(shù)據(jù)(如用戶信息、計(jì)費(fèi)規(guī)則)存儲(chǔ)在關(guān)系型數(shù)據(jù)庫中。
- 數(shù)據(jù)處理層:利用MapReduce或Spark對(duì)Hadoop中的數(shù)據(jù)進(jìn)行ETL(提取、轉(zhuǎn)換、加載)、數(shù)據(jù)清洗和聚合分析,結(jié)果可導(dǎo)入關(guān)系型數(shù)據(jù)庫供業(yè)務(wù)系統(tǒng)使用。
- 服務(wù)接口層:提供統(tǒng)一的RESTful API或數(shù)據(jù)服務(wù),支持前端應(yīng)用、報(bào)表系統(tǒng)和實(shí)時(shí)監(jiān)控平臺(tái)從混合數(shù)據(jù)源中獲取信息。
三、優(yōu)勢(shì)與應(yīng)用場(chǎng)景
混合架構(gòu)在電力用采大數(shù)據(jù)服務(wù)中具有顯著優(yōu)勢(shì):
- 高可擴(kuò)展性:Hadoop支持橫向擴(kuò)展,輕松應(yīng)對(duì)數(shù)據(jù)量增長。
- 成本效益:利用Hadoop存儲(chǔ)低成本的歷史數(shù)據(jù),降低硬件投資。
- 實(shí)時(shí)與批量處理結(jié)合:關(guān)系型數(shù)據(jù)庫處理實(shí)時(shí)查詢,Hadoop處理離線分析,滿足多樣業(yè)務(wù)需求。
- 數(shù)據(jù)完整性:通過關(guān)系型數(shù)據(jù)庫保障事務(wù)一致性,避免數(shù)據(jù)沖突。
典型應(yīng)用包括用電負(fù)荷預(yù)測(cè)、故障檢測(cè)、用戶行為分析和智能計(jì)費(fèi)。
四、挑戰(zhàn)與優(yōu)化策略
盡管混合架構(gòu)優(yōu)勢(shì)明顯,但也面臨數(shù)據(jù)同步、系統(tǒng)復(fù)雜性和運(yùn)維難度等挑戰(zhàn)。為此,可采取以下優(yōu)化措施:
- 使用數(shù)據(jù)同步工具(如Sqoop、Kafka)實(shí)現(xiàn)Hadoop與關(guān)系型數(shù)據(jù)庫之間的高效數(shù)據(jù)流轉(zhuǎn)。
- 引入數(shù)據(jù)倉庫技術(shù)(如Hive)簡(jiǎn)化Hadoop查詢,提升開發(fā)效率。
- 實(shí)施監(jiān)控與告警機(jī)制,確保系統(tǒng)穩(wěn)定運(yùn)行。
基于Hadoop和關(guān)系型數(shù)據(jù)庫的電力用采大數(shù)據(jù)混合服務(wù)架構(gòu),通過互補(bǔ)技術(shù)融合,不僅提升了數(shù)據(jù)處理能力,還推動(dòng)了電力行業(yè)的智能化轉(zhuǎn)型。未來,隨著邊緣計(jì)算和人工智能技術(shù)的融入,這一架構(gòu)將進(jìn)一步完善,為電力系統(tǒng)提供更強(qiáng)大的數(shù)據(jù)支撐。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.cdmbw.com/product/32.html
更新時(shí)間:2026-02-19 21:25:38